
统计学习方法 K邻近法 Ch3
数学补课
k 邻近法
假定实例的类别已确定,输入为实例的特征向量,输出为实例的类别,
分类时,输入新的实例,根据类别,通过多数表决方式进行预测。
k值选择(不宜过大过小),距离度量分(如欧式距离),类决策规则(如多数表决)是 k 邻近法的三个基本要素.
- 算法

KNN 与 k-d 数算法
如果划分超矩形区域?简单如例子,复杂点,可以计算所有数据点在每个维度上的数值的方差,方差越大说明数据越分散,选择其作为当前节点的划分维度。
- 搜索例子
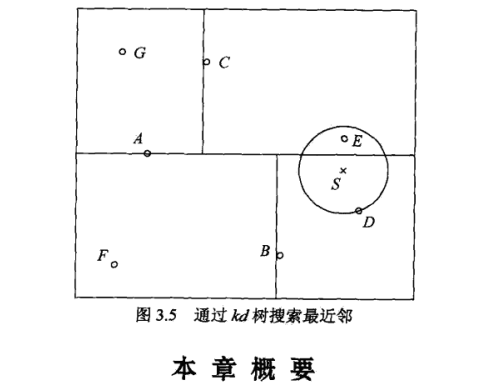
k-d 数情况:
root A left B (D,F) right C (E,G)
1.先找到二叉查找找到包含 S 的叶节点 D,min_p = D.计算球半径 rSD;
2.再算 D 父节点 B 到 S 的距离,rBD > rSD 说明 B 的左节点到 S 的距离只会更远,没有必要搜索 F 了;
3.继续向上查找。B 的兄弟节点为 C,C 与圆相交的的区域有实例 E,即 min_p=E,
4.如此向上,直至搜索完毕。
例子
-
手写识别 每个字母,数字对应一张二值化的图(01010..),展开就是一个 1xk 的向量,对应到 knn 中就是某个类中的某个 k 维实例点,比如 0-每个类下可能有若干个
训练样本,所有的训练样本组成一个训练集. 拿到新的测试数据时,直接按 knn 算法可以得到测试数据的分类结果。 -
电影分类
如何确定电影类型?先要确定一个评价矩阵[],每个元素对应一个评价项目,矩阵空间即决定了所有的电影类型,如[011101]代表[平静音乐(无,0),惊吓画面(有,1),打斗画面(有,1),观众评价(有,1),…],从已有数据如何提炼出[011101]来?就是数据的特征提取与标注的问题…之后也是用 knn 来分类就好
