
Libevent buffer机制
English ref libevent 中的 proactor
buffer 机制
buffer 机制在大量的场合都会用到,也可以叫做缓冲队列。缓冲的作用本质上都是解决同步的问题。在大量的 recv data 处理不过来时,可以先放入 recv buffer;大量 send 不能一下 send 出去时,也可以先放入 send buffer。项目中的用到的就有:
- screencap-rotate-yuv-encoder-send
- read-jpg decode-framebuffer
- all data cache 的 task queue
在实现上,也是用同步原语 + 数据的内存分配,对队列的收尾进行控制。一般编程语言都有成型的队列结构,不管他叫blocking queue,tasking queue,还是message queue。
evbuffer
libevent 将缓冲数据都存放到 buffer 指针中,buffer 用evbuffer_chain封装,通过一个个的 evbuffer_chain 连成的链表可以存放很多的缓冲数据, 用 1 个evbuffer的结构作为整个 buffer_chain 的管理,类似链表头。
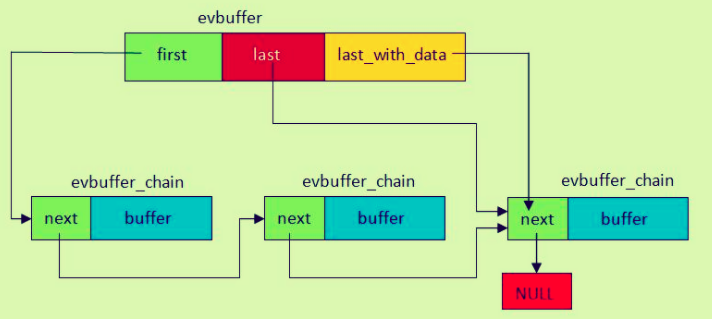
libevent 的精巧的在于,根据不用的用途定义了不同的 buffer chain 以满足不同的性能需求。
#define EVBUFFER_MMAP 0x0001 /**< memory in buffer is mmaped */
#define EVBUFFER_SENDFILE 0x0002 /**< a chain used for sendfile */
#define EVBUFFER_REFERENCE 0x0004 /**< a chain with a mem reference */
#define EVBUFFER_IMMUTABLE 0x0008 /**< read-only chain */
/** a chain that mustn't be reallocated or freed, or have its contents
* memmoved, until the chain is un-pinned. */
#define EVBUFFER_MEM_PINNED_R 0x0010
#define EVBUFFER_MEM_PINNED_W 0x0020
#define EVBUFFER_MEM_PINNED_ANY (EVBUFFER_MEM_PINNED_R|EVBUFFER_MEM_PINNED_W)
/** a chain that should be freed, but can't be freed until it is
* un-pinned. */
#define EVBUFFER_DANGLING 0x0040
evbuffer_add
使用 buffer 机制时,首先要把数据用 bufferchain 封装,再把 bufferchain 添加到 evbuffer 的队列中。
自己项目里用到了简单的队列,消费队列时,每次都释放了 chain 和 chain data,evbuffer 似乎不是这么设计的,也许还是为了提高效率,减少入列时的 malloc 等动作。在每次分配 chain 和 data buffer 时,会分配一个足够大的 data buffer(512,1024,2048),如果本次没有用完,下次可以接着使用上次没有用完 data buffer 的 chain。
chain 还分只读和读写属性,只读的 chain 不能更新 data buffer 的大小,而可写的还可以扩充 chain 的 data buffer 的大小。
想象一个场景:
某client 源源不断的往libevent server发数据,每次数据量不固定,比`128 512 1024...`,server端如果用evbuffer机制,client足够快,server反应不过来,则在buffer callback里 一次就能接收到多笔数据如`128+512+1024=1654`.需要业务层去区分每哪笔数据。(如128是命令,512是语音,1024是图像)。
在接受第1个128时,evbuffer chain分配的data buffer是1024 ,在下1个512 到来时,如果当前chain还没有被消费,则可以用来继续存放512; 下1个1024 来临时,仍然chain没有被消费:
如果是`可写`chain,则可以基于当前chain扩充data buffer size ,比如2048;
如果是`只读`chain, 则只能把剩余的空间(384=1024-128-512)填满当前chain,再用一个新的chain(1024)去装剩余的数据(1024-384)。
尽管我们项目还没有抠malloc这种操作对系统性能影响的地步,但是确实如此实现是可以提升性能的。
另外自己项目里实现的队列在添加时,都是从队尾加,消费时,都是从队列头取。当中间缓冲较多时,如果为了提高某次添加的效率,也可以考虑直接在队列头添加 event。
evbuffer_chain_insert的过程:
- 添加是从 last_with_datap 的 chain 开始,而不是队尾的 chain;
- 如果有合适的 last_with_datap, 则要释放 last_with_datap 后所有的 chain,再把要 insert 的 chain 放在最后;
疑问:为何队列里会没有数据的 chain,而需要在 insert 时将他们又释放掉?
其实有这样的chain,这种节点一般是用于预留空间的。预留空间这个概念在STL中是很常见的,它的主要作用是使得当下次添加数据时,无需额外申请空间就能保存数据。
evbuffer 的使用参考。
bufferevent
-
当然封装了 read write 2 个 event 和 event_base;
-
对应用到了 input/output 2 个 evbuffer 缓冲区,evbuffer 都是头取尾放。
在 fd 收到数据时,数据从 fd 添加 input_evbuffer 的尾部(bufferevent_readcb 来完成),用户从 input_evbuffer 的头部拿数据;
往 fd 写数据时,用户将数据先添加到 output_evbuffer 的尾部,然后从头部取出发送给 fd(bufferevent_readcb)来完成。
- 提供了
水位及对应的回调注册,当缓冲区数据到达某个上下限时,可以触发回调;
读低水位 readed > read_lb : 触发读回调
读高水位 readed > read_hb: 无回调,但表示 evbuffer 的最高限制在 read_hb,用户必须尽快取走数据
水位的逻辑
在 read_cb 里,计算当前 evbuffer 里还有多少可以读取:howmuch= hb-current_have howmuch 有可能超过了本次能读的最大值 read_rlim if(howmuch> read_rlim) howmuch=read_rlim
速率限制模型
bufferevent api
struct bufferevent * bufferevent_socket_new(struct event_base *base, evutil_socket_t fd, int options)
/** Options that can be specified when creating a bufferevent */
enum bufferevent_options {
/** If set, we close the underlying file
* descriptor/bufferevent/whatever when this bufferevent is freed. */
BEV_OPT_CLOSE_ON_FREE = (1<<0),
/** If set, and threading is enabled, operations on this bufferevent
* are protected by a lock */
BEV_OPT_THREADSAFE = (1<<1),
/** If set, callbacks are run deferred in the event loop. */
BEV_OPT_DEFER_CALLBACKS = (1<<2),
/** If set, callbacks are executed without locks being held on the
* bufferevent. This option currently requires that
* BEV_OPT_DEFER_CALLBACKS also be set; a future version of Libevent
* might remove the requirement.*/
BEV_OPT_UNLOCK_CALLBACKS = (1<<3)
};
- void bufferevent_setcb(struct bufferevent *bufev, bufferevent_data_cb readcb, bufferevent_data_cb writecb, bufferevent_event_cb eventcb, void *cbarg)
- int bufferevent_enable(struct bufferevent *bufev, short event)
