
Deep learning Lihongyi ppt
理解可以顺这 ng 课程讲的全连接网络来.
softmax
ng 课程里,output layer 是一个多元 logistic 模型.这里提到了softmax来做 output layer 的 activate function.
当损失函数是交叉熵时.softmax 由于求导梯度很方便
- 损失函数
Linear regression 用损失函数是
mse.
Linear regression 用的log损失.
SVM 可看成用的hinger损失.
决策树时,分裂特征的标准为条件熵,gini等
dropout
有点类似 ensemable 的思想,每次 dropout 实际上在训练不同的网络,把他们组合起来,可以减少过拟合的风险。
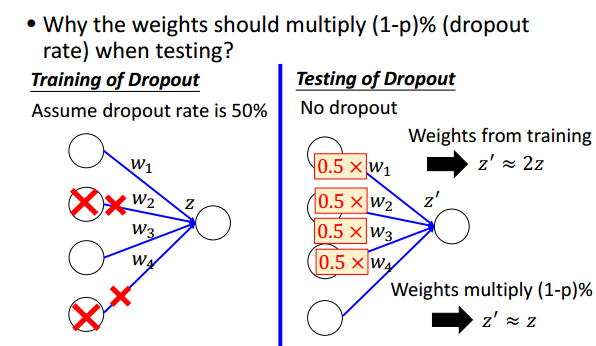
dropout rate = p%,训练好后得到 w,在 test 时,w=w*(1-p%).why?
mini-batch
梯度下降时,前面 ng 的课讲过了,SGD,BGD,Min-batch GD 的区别,可以理解 Min-batch GD 可以 faster,但是 better?为什么会 better.
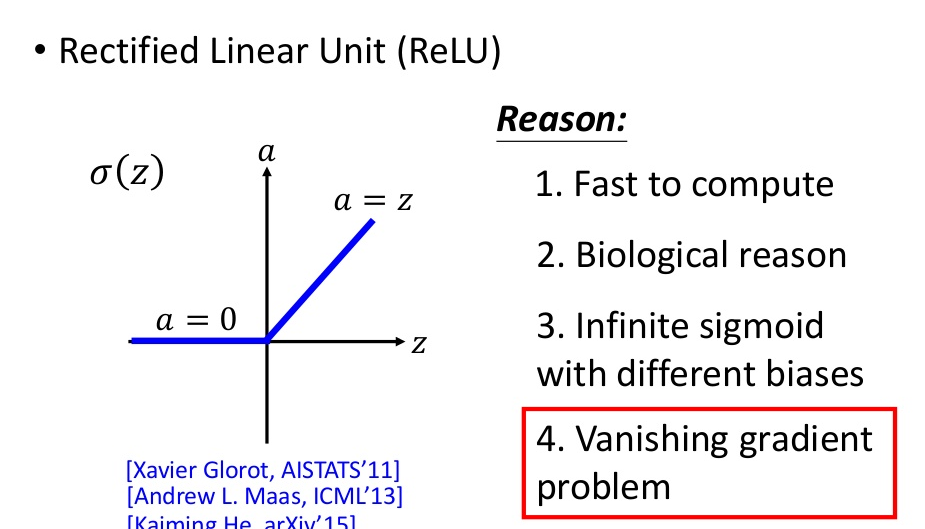
gradient vanish
过深的网络,容易出现梯度消失的问题,用更好的 activation function!
对应的还有梯度爆炸的问题.
最新的解决思路是highway network和深度残差学习.
Relu 激活函数
Maxout
ReLU 是 maxout 的一个特例
learning rate
lr 太大,梯度跳跃,可能迭代不收敛 lr 太小,收敛太慢
随着迭代增加,慢慢减少 lr.
不同参数用不同的 lr.
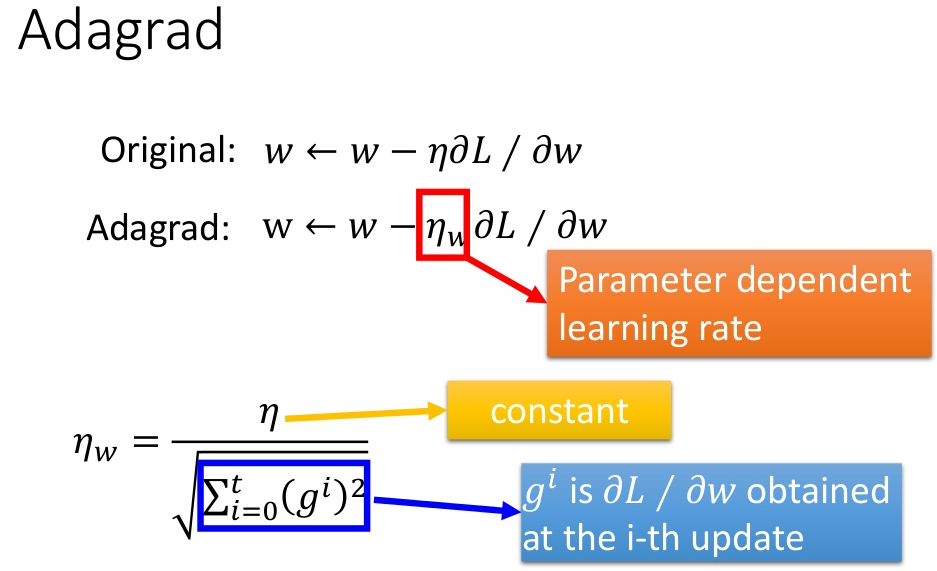
- adagrad
根据梯度自适应调节学习率的方法
还有很多调整方法,RMSprop,Adadelta,AdaSecant,Adam,Nadam…
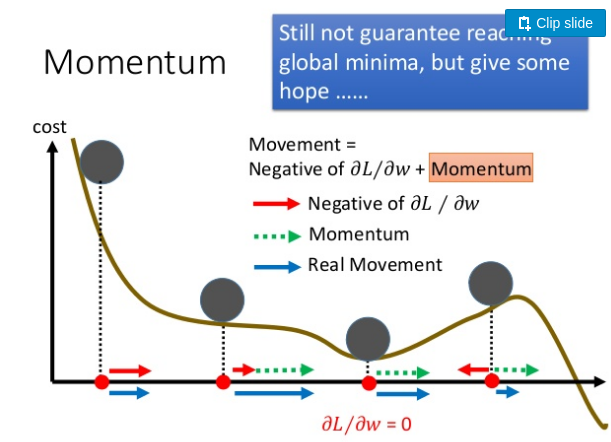
- Adam
用动量的思想解决因为梯度太小而陷入局部最优的问题,根据该原理有adam算法
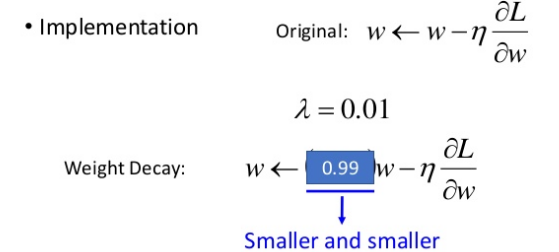
Weight Decay
权重萎缩.有些特征对最后的分类并没有帮助,在梯度下降时,该特征对应的参数可加一个萎缩系数,慢慢让其作用权重越来越小
DNN
和全连接 FNN 的结构类似,只是激活函数可能换成了 ReLU,output layer 换成 softmax 之类的
