
Zeromq 可靠req Rep模式
- Client-Side Reliability (Lazy Pirate Pattern)
- Basic Reliable Queuing (Simple Pirate Pattern)
- Robust Reliable Queuing (Paranoid Pirate Pattern)
Client-Side Reliability (Lazy Pirate Pattern)
还没 get 到为啥要 lazy pirate… 核心就是 client 别死等 rep,timeout,再加重试:
#
# Lazy Pirate client
# Use zmq_poll to do a safe request-reply
# To run, start lpserver and then randomly kill/restart it
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
from __future__ import print_function
import zmq
REQUEST_TIMEOUT = 2500
REQUEST_RETRIES = 3
SERVER_ENDPOINT = "tcp://localhost:5555"
context = zmq.Context(1)
print("I: Connecting to server…")
client = context.socket(zmq.REQ)
client.connect(SERVER_ENDPOINT)
poll = zmq.Poller()
poll.register(client, zmq.POLLIN)
sequence = 0
retries_left = REQUEST_RETRIES
while retries_left:
sequence += 1
request = str(sequence).encode()
print("I: Sending (%s)" % request)
client.send(request)
expect_reply = True
while expect_reply:
socks = dict(poll.poll(REQUEST_TIMEOUT))
if socks.get(client) == zmq.POLLIN:
reply = client.recv()
if not reply:
break
if int(reply) == sequence:
print("I: Server replied OK (%s)" % reply)
retries_left = REQUEST_RETRIES
expect_reply = False
else:
print("E: Malformed reply from server: %s" % reply)
else:
print("W: No response from server, retrying…")
# Socket is confused. Close and remove it.
client.setsockopt(zmq.LINGER, 0)
client.close()
poll.unregister(client)
retries_left -= 1
if retries_left == 0:
print("E: Server seems to be offline, abandoning")
break
print("I: Reconnecting and resending (%s)" % request)
# Create new connection
client = context.socket(zmq.REQ)
client.connect(SERVER_ENDPOINT)
poll.register(client, zmq.POLLIN)
client.send(request)
context.term()
输出:
client:
I: Server replied OK (b'5')
I: Sending (b'6')
I: Server replied OK (b'6')
I: Sending (b'7')
W: No response from server, retrying…
I: Reconnecting and resending (b'7')
W: No response from server, retrying…
I: Reconnecting and resending (b'7')
W: No response from server, retrying…
E: Server seems to be offline, abandoning
server:
I: Normal request (b'1')
I: Normal request (b'2')
I: Normal request (b'3')
I: Normal request (b'4')
I: Normal request (b'5')
I: Normal request (b'6')
I: Simulating a crash
Basic Reliable Queuing (Simple Pirate Pattern)
之前提到的 load balancing broker 已经可以解决某些 worker 挂掉的场景的了,client 替换为上面的稳健 client 即可.
Robust Reliable Queuing (Paranoid Pirate Pattern)
但是上面的 broker 挂掉了怎么办?用 heartbeating 告诉 worker,broker 还活着!如果 broker 挂了(超时),worker 给 3 次机会,如最后还是收不到心跳,可以认为 broker 真的挂了.
worker 实现:
from random import randint
import time
import zmq
HEARTBEAT_LIVENESS = 3
HEARTBEAT_INTERVAL = 1
INTERVAL_INIT = 1
INTERVAL_MAX = 32
# Paranoid Pirate Protocol constants
PPP_READY = "\x01" # Signals worker is ready
PPP_HEARTBEAT = "\x02" # Signals worker heartbeat
def worker_socket(context, poller):
"""Helper function that returns a new configured socket
connected to the Paranoid Pirate queue"""
worker = context.socket(zmq.DEALER) # DEALER
identity = "%04X-%04X" % (randint(0, 0x10000), randint(0, 0x10000))
worker.setsockopt(zmq.IDENTITY, identity)
poller.register(worker, zmq.POLLIN)
worker.connect("tcp://localhost:5556")
worker.send(PPP_READY)
return worker
context = zmq.Context(1)
poller = zmq.Poller()
liveness = HEARTBEAT_LIVENESS
interval = INTERVAL_INIT
heartbeat_at = time.time() + HEARTBEAT_INTERVAL
worker = worker_socket(context, poller)
cycles = 0
while True:
socks = dict(poller.poll(HEARTBEAT_INTERVAL * 1000))
# Handle worker activity on backend
if socks.get(worker) == zmq.POLLIN:
# Get message
# - 3-part envelope + content -> request
# - 1-part HEARTBEAT -> heartbeat
frames = worker.recv_multipart()
if not frames:
break # Interrupted
if len(frames) == 3:
# Simulate various problems, after a few cycles
cycles += 1
if cycles > 3 and randint(0, 5) == 0:
print "I: Simulating a crash"
break
if cycles > 3 and randint(0, 5) == 0:
print "I: Simulating CPU overload"
time.sleep(3)
print "I: Normal reply"
worker.send_multipart(frames)
liveness = HEARTBEAT_LIVENESS
time.sleep(1) # Do some heavy work
elif len(frames) == 1 and frames[0] == PPP_HEARTBEAT:
print "I: Queue heartbeat"
liveness = HEARTBEAT_LIVENESS
else:
print "E: Invalid message: %s" % frames
interval = INTERVAL_INIT
else:
liveness -= 1
if liveness == 0:
print "W: Heartbeat failure, can't reach queue"
print "W: Reconnecting in %0.2fs…" % interval
time.sleep(interval)
if interval < INTERVAL_MAX:
interval *= 2
poller.unregister(worker)
worker.setsockopt(zmq.LINGER, 0)
worker.close()
worker = worker_socket(context, poller)
liveness = HEARTBEAT_LIVENESS
if time.time() > heartbeat_at:
heartbeat_at = time.time() + HEARTBEAT_INTERVAL
print "I: Worker heartbeat"
worker.send(PPP_HEARTBEAT)
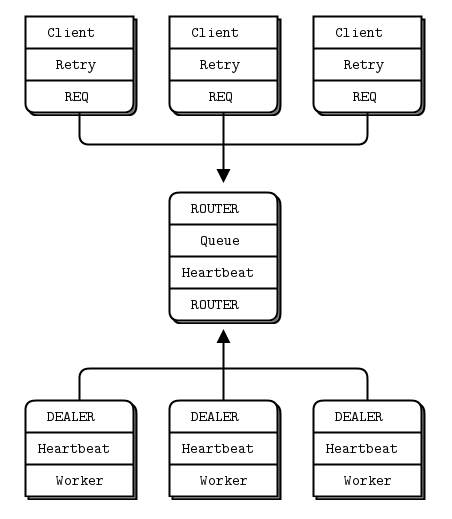
注意的几个问题:
- 负载太重的情况,发方不用定时发,可以在负载轻微以后再发,收方可把收到的数据都看成对方
还活着.
2.push-pull 模式会 queue 心跳,比如 pull 挂了,重新上线后,收到 n 多心跳!避免的方式就是 push 方要知道对方挂了,就不要定时发了.
最后就是所谓的 ping-pong 心跳,相互监听,挺妥.比如上面的 worker 也回应心跳给 broker. 以上场景自己做 wifi 互联也用到过,不算太特殊.
又见大神操作:所有 zeromq 可能用到的自定义协议,全部整理清楚,比如上面这个心跳协议
Service-Oriented Reliable Queuing (Majordomo Pattern)
继承自上面的 PPP,叫 MDP,具体协议在这里
service-oriented 在协议里的体现就是指定 service name.重连谁,重发给谁都有明确目标.
除了 requset,reply,heartbeating,在协议里还定义了 disconnect 的命令.
在连接后,broker 和 worker 都可向对方主动发 disconnect;
borker 收到任何不符合协议的 invalid 消息,应该发送 disconnect 给对方;并丢弃 invalid 消息.
worker 收到 disconnect,做 1 次重连(不是 broker 主动 disconnect 吗?这里有点诡异)
实现
client 核心: poll 接收 reply,timeout 后,reconnect 重发 request,允许重试 3 次;
worker 核心: heartbeating
最难的是 broker 了,先直接上作者的说明:
The Majordomo Protocol lets us handle both clients and workers on a single socket. This is nicer for those deploying and managing the broker: it just sits on one ZeroMQ endpoint rather than the two that most proxies need.
The broker implements all of MDP/0.1 properly (as far as I know), including disconnection if the broker sends invalid commands, heartbeating, and the rest.
It can be extended to run multiple threads, each managing one socket and one set of clients and workers. This could be interesting for segmenting large architectures. The C code is already organized around a broker class to make this trivial.
A primary/failover or live/live broker reliability model is easy, as the broker essentially has no state except service presence. It's up to clients and workers to choose another broker if their first choice isn't up and running.
The examples use five-second heartbeats, mainly to reduce the amount of output when you enable tracing. Realistic values would be lower for most LAN applications. However, any retry has to be slow enough to allow for a service to restart, say 10 seconds at least.
这里 broker 实现不是采用 ROUTER-DEALER,而只是用了1个 ROUTER,这里全是黑人问号了…因为 MDP 协议的特殊性?
仔细看 MDP,client 和 worker 是通过 frame 可直接辨认的:
client:
Frame 1: "MDPC01" (six bytes, representing MDP/Client v0.1)
worker:
Frame 1: "MDPW01" (six bytes, representing MDP/Worker v0.1)
当 ROUTER 收到消息时,通过这个可区分消息流向.
if (MDP.C_CLIENT == header):
self.process_client(sender, msg)
elif (MDP.W_WORKER == header):
self.process_worker(sender, msg)
else:
logging.error("E: invalid message:")
dump(msg)
broker 如何把一个指定 service name 的 client msg 分发到 worker 的?
def dispatch(self, service, msg):
"""Dispatch requests to waiting workers as possible"""
assert (service is not None)
if msg is not None:# Queue message if any
service.requests.append(msg)
logging.info('service.requests = %s in dispatch for service:%s ',service.requests,service.name)
self.purge_workers()
# waiting里是service对应的n个worker, service.request是client发送到service的requests
while service.waiting and service.requests:
msg = service.requests.pop(0)
worker = service.waiting.pop(0)
self.waiting.remove(worker)
self.send_to_worker(worker, MDP.W_REQUEST, None, msg)
2 个很关键的数据 object:
class Service(object):
"""a single Service"""
name = None # Service name
requests = None # List of client requests
waiting = None # List of waiting workers
def __init__(self, name):
self.name = name
self.requests = []
self.waiting = []
class Worker(object):
"""a Worker, idle or active"""
identity = None # hex Identity of worker
address = None # Address to route to
service = None # Owning service, if known
expiry = None # expires at this point, unless heartbeat
def __init__(self, identity, address, lifetime):
self.identity = identity
self.address = address
self.expiry = time.time() + 1e-3*lifetime
流程
client -> broker -> worker
- REQ client send [b’MDPC01’, b’echo’, b’Hello world’]
client 端的 REQUEST, ‘‘自动被 REQ 添加,如果是 DEALER,则需要手动增加,
- ROUTER broker receive: [b’\x00k\x8bEi’, b’’, b’MDPC01’, b’echo’, b’Hello world’]
ROUTER recv 后增加了 from-peer address
- ROUTER send to worker(DEALER): [b’\x00k\x8bEj’, b’’, b’MDPW01’, b’\x02’, b’\x00k\x8bEi’, b’’, b’Hello world’] broker 发送给 workder 的 REQUEST, ROUTER 发送前确认 to-peer 的 address,
worker -> broker -> client
- DEALER worker send REPLY [b’\x00k\x8bEi’, b’’, b’MDPW01’, b’\x03’, b’\x00k\x8bEh’, b’’, b’Hello world’] to ROUTER broker
worker 端发送的 REPLY.
- ROUTER broker to REQ client: [b’\x00k\x8bEh’, b’’, b’MDPC01’, b’echo’, b’Hello world’] broker 端发送的 REPLY
Asynchronous Majordomo Pattern
broker 演进总结
简单的 1-on-1 REQ-REP ;
普通的 rr(round robin)broker 的支持 n-req n-rep.
考虑效率用 lb(对象存储、块存储) broker;
再效率!用集群, 用能平衡云端负载的 advanced lb broker;
好了,考虑可靠性,用 reliable broker.
层层深入,可以的.
###
