
Linux 动态链接
注意:共享对象都用 so 代替.
why 动态链接? 从共享说起
静态链接没有共享机制,有改动也是整体要重新编译,耦合太重.
静态链接生成的执行 elf,所有的代码在运行前都准备完毕, 多个进程引用同样的代码段(somecode.o)会造成多个复制,浪费了空间.
共享库的基本思想就是,动态库(*.so)和其他部分独立开,好处:
- 装载到内存独有 1 份,其他进程需要使用,就可以共享它.
- 库和其他部分分离,解耦合后方便开发.
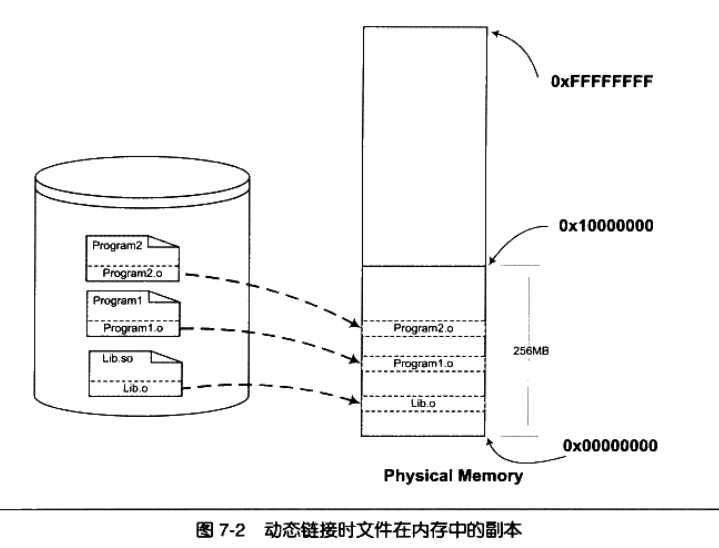
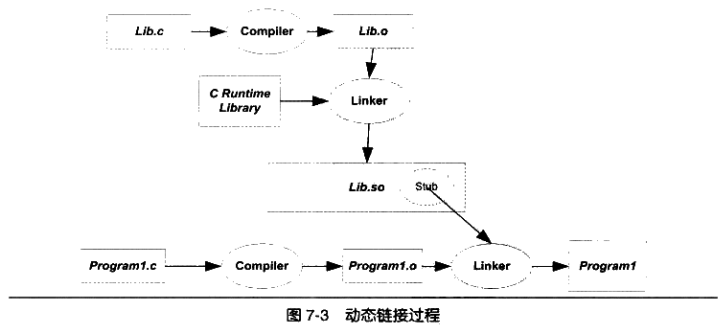
动态链接的过程:
装载重定位
静态链接里的重定位,发生在编译期间的链接过程里,叫静态重定位.
共享库虽然分离了,但还是要和其他部分作为 1 个整体才能使用.
只不过现在让原来在静态链接里的链接过程推迟,等所有部分(so 和其他执行模块)全部装载了,有地址了,才能确定最终地址. 这个过程就是装载后链接,即动态链接.它的运行时机是装载后,运行前.
1 个简单的进程空间展示,可以看到 ld.so 就是动态链接器.
➜ compile-link-lib cat /proc/9591/maps
559d43d7c000-559d43d7d000 r-xp 00000000 08:06 4462250 /home/bravo/Projects/Cpp/compile-link-lib/ab
559d43f7c000-559d43f7d000 r--p 00000000 08:06 4462250 /home/bravo/Projects/Cpp/compile-link-lib/ab
559d43f7d000-559d43f7e000 rw-p 00001000 08:06 4462250 /home/bravo/Projects/Cpp/compile-link-lib/ab
559d4413d000-559d4415e000 rw-p 00000000 00:00 0 [heap]
7fd5343b8000-7fd53459f000 r-xp 00000000 08:06 14160558 /lib/x86_64-linux-gnu/libc-2.27.so
7fd53459f000-7fd53479f000 ---p 001e7000 08:06 14160558 /lib/x86_64-linux-gnu/libc-2.27.so
7fd53479f000-7fd5347a3000 r--p 001e7000 08:06 14160558 /lib/x86_64-linux-gnu/libc-2.27.so
7fd5347a3000-7fd5347a5000 rw-p 001eb000 08:06 14160558 /lib/x86_64-linux-gnu/libc-2.27.so
7fd5347a5000-7fd5347a9000 rw-p 00000000 00:00 0
7fd5347a9000-7fd5347d0000 r-xp 00000000 08:06 14160530 /lib/x86_64-linux-gnu/ld-2.27.so
7fd5349b3000-7fd5349b5000 rw-p 00000000 00:00 0
7fd5349d0000-7fd5349d1000 r--p 00027000 08:06 14160530 /lib/x86_64-linux-gnu/ld-2.27.so
7fd5349d1000-7fd5349d2000 rw-p 00028000 08:06 14160530 /lib/x86_64-linux-gnu/ld-2.27.so
7fd5349d2000-7fd5349d3000 rw-p 00000000 00:00 0
7ffc3193b000-7ffc3195c000 rw-p 00000000 00:00 0 [stack]
7ffc319a7000-7ffc319aa000 r--p 00000000 00:00 0 [vvar]
7ffc319aa000-7ffc319ac000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
因此也会像静态链接一样,存在重定位的符号表,包括地址修正的机制等.
地址无关码(Position-independent code,PIC)
反过来看装载重定位的地址修正,假设修正的是函数代码,那意味着代码改了,已经不同于在 so 库的了,是不是又得有份拷贝?对单个进程可能不觉得有问题,但是多个进程使用 1 个 a,每个都修正,产生副本,又回到老路,内存并没有真正的节省.
自然的想法是,如果让改动的部分最小,其余的不改动的部分就能共享了.
编译参数 -fPIC, 解决了上面的问题,叫地址无关码(PIC).
思想是: 把 so 的指令中可能修改的部分单独分离,设计为另外的代码段(.plt)和另外的跳转地址存储的数据段(.got),其余的指令部分变为无关代码可共享,数据每个进程可独有 1 份,但是无关代码可以完全共享,各自进程不用产生副本,做到真正的省内存.
要强调的是,修正的位置都是地址引用.(还分代码和数据) 举个例子:
static int a;
extern int b;
extern int ext();
int * c = &b ;//数据引用外部变量
void bar()
{
a = 1; //代码引用模块内static变量
b = 2; //代码引用模块外变量
}
void foo()
{
bar(); //代码引用模块内函数
ext(); //代码引用模块外函数
}
共享模块,可以定义 1 个符号的访问属性, 导出符号才能被外部访问,否则只能模块内访问.
__declspec(dllexport) //导出符号
__declspec(dllimport) //不导出,只能模块内引用.
编译成 so 库:
gcc solib.c -shared -o solib.so -fPIC
看汇编代码,不相关的去掉咯
➜ compile-link-lib objdump -d solib.so
solib.so: file format elf64-x86-64
Disassembly of section .plt:
0000000000000510 <.plt>:
510: ff 35 f2 0a 20 00 pushq 0x200af2(%rip) # 201008 <_GLOBAL_OFFSET_TABLE_+0x8>
516: ff 25 f4 0a 20 00 jmpq *0x200af4(%rip) # 201010 <_GLOBAL_OFFSET_TABLE_+0x10>
51c: 0f 1f 40 00 nopl 0x0(%rax)
0000000000000520 <ext@plt>:
520: ff 25 f2 0a 20 00 jmpq *0x200af2(%rip) # 201018 <ext>
526: 68 00 00 00 00 pushq $0x0
52b: e9 e0 ff ff ff jmpq 510 <.plt>
0000000000000530 <bar@plt>:
530: ff 25 ea 0a 20 00 jmpq *0x200aea(%rip) # 201020 <bar+0x2009f6>
536: 68 01 00 00 00 pushq $0x1
53b: e9 d0 ff ff ff jmpq 510 <.plt>
Disassembly of section .plt.got:
0000000000000540 <__cxa_finalize@plt>:
540: ff 25 9a 0a 20 00 jmpq *0x200a9a(%rip) # 200fe0 <__cxa_finalize>
546: 66 90 xchg %ax,%ax
Disassembly of section .text:
000000000000062a <bar>:
62a: 55 push %rbp
62b: 48 89 e5 mov %rsp,%rbp
62e: c7 05 fc 09 20 00 01 movl $0x1,0x2009fc(%rip) # 201034 <a>
635: 00 00 00
638: 48 8b 05 99 09 20 00 mov 0x200999(%rip),%rax # 200fd8 <b>
63f: c7 00 02 00 00 00 movl $0x2,(%rax)
645: 90 nop
646: 5d pop %rbp
647: c3 retq
0000000000000648 <foo>:
648: 55 push %rbp
649: 48 89 e5 mov %rsp,%rbp
64c: b8 00 00 00 00 mov $0x0,%eax
651: e8 da fe ff ff callq 530 <bar@plt>
656: b8 00 00 00 00 mov $0x0,%eax
65b: e8 c0 fe ff ff callq 520 <ext@plt>
660: 90 nop
661: 5d pop %rbp
662: c3 retq
上面 4 种引用方式, 具体分析:
- 模块内访问函数(foo->bar)
模块地址确定后,模块内的函数相对位置不变化,通过当前的 pc(rip)位置,加上相对偏移,就能找到对方的位置, 不需要特殊处理.
这里看到, 实际是调用了 bar@plt,是为了规避全局符号介入的问题,放到下面讲.
- 模块内访问 static 数据(a=2)
装载后的 segment 来说,数据块和代码块的位置也是相对固定的,也就是只要有当前的 pc(rip),加上某个相对量,就能访问到内部的数据段(.data)上的数据
62e: c7 05 fc 09 20 00 01 movl $0x1,0x2009fc(%rip) # 201034 <a>
- 模块外访问数据;(b=1)
638: 48 8b 05 99 09 20 00 mov 0x200999(%rip),%rax # 200fd8 <b>
63f: c7 00 02 00 00 00 movl $0x2,(%rax)
先保存 1 个相对 rip 为 0x200999 的地址到 rax,然后将该地址赋值为 2;
地址可以算出来:
>>> hex(0x200999+0x638+7)
'0x200fd8'
这个地址是什么? 是叫全局偏移表(.got, Golbal Offset Table),动态编译 so 时,为了访问模块外的全局对象,又为了做成位置无关码的形式,专门新增了这么 1 个数据段.
查看下,可以看到.got 的地址就是它.
➜ compile-link-lib readelf -R .got solib.so
Hex dump of section '.got':
0x00200fd8 00000000 00000000 00000000 00000000 ................
0x00200fe8 00000000 00000000 00000000 00000000 ................
0x00200ff8 00000000 00000000 ........
或者用 objdump 看:
➜ compile-link-lib objdump -R solib.so
solib.so: file format elf64-x86-64
DYNAMIC RELOCATION RECORDS
OFFSET TYPE VALUE
...
000000000200fd8 R_X86_64_GLOB_DAT b
000000000201018 R_X86_64_JUMP_SLOT ext
0000000000201020 R_X86_64_JUMP_SLOT bar
在含有 b 的模块装载后,可想而知,ld 一定会修改这个 got 表,从而让上面的赋值到真正的 b 地址中.
GOT 的作用也很明显了: 在装载前,数据重定位的入口设计为访问 GOT 表,而 GOT 再装载后可以被 ld 修正,再确定具体值!
- 模块外访问函数;(foo->ext)
函数引用自然也能用 GOT 来实现.
先比较下有无 GOT:
无GOT:
1.编译so-->遇到外部的引用函数--->先用个临时地址callq过去--->地址标记为重定位符号-->...
2.进程p1使用so-->装载后,开始重定位--->修正该地址,就是改代码,必须拷贝--->修改后的副本再装载--->p1运行
3.进程p2使用so-->装载后,开始重定位--->修正该地址,就是改代码,改法和p1不一样!必须另外的拷贝--->修改后的副本再装载--->p2运行
有GOT:
1. 编译so--->遇到外部的引用函数-->把地址放到got表某处,callq到这个地址-->...
2. 进程p1使用so--->装载后,根据实际符号填写got--->p1直接使用共享库映射的代码,不用修改,不用拷贝--->p1运行
3. 进程p2使用so--->装载后,根据实际符号填写got--->p1直接使用代码--->p2运行
延迟绑定(PLT)
GOT 做到了让 so 在内存的任意位置可以加载,但是每次 ld 都在启动前,到确定 GOT 的地址,数据多了性能上不去。如何优化动态链接时的性能?
延迟绑定技术.
基本思想是,不着急一开始就修改GOT,而是程序第1次运行到某个函数时,才进行修改,也即地址绑定.
看 foo 调用 ext 的汇编, callq 的执行的是ext@plt
0000000000000648 <foo>:
648: 55 push %rbp
649: 48 89 e5 mov %rsp,%rbp
64c: b8 00 00 00 00 mov $0x0,%eax
651: e8 da fe ff ff callq 530 <bar@plt>
656: b8 00 00 00 00 mov $0x0,%eax
65b: e8 c0 fe ff ff callq 520 <ext@plt>
660: 90 nop
661: 5d pop %rbp
662: c3 retq
ext@plt 是额外生成的代码段,肯定不是原来的 ext.
ext@plt 里,先 jump 到 1 个地址执行. 这个很像 GOT,可以看到有这么个符号的.
0000000000000520 <ext@plt>:
520: ff 25 f2 0a 20 00 jmpq *0x200af2(%rip) # 201018 <ext>
526: 68 00 00 00 00 pushq $0x0
52b: e9 e0 ff ff ff jmpq 510 <.plt>
符号在动态重定位函数符号表(.rela.plt)也有:
➜ solib readelf -r libtest.so
Relocation section '.rela.dyn' at offset 0x408 contains 8 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000200e48 000000000008 R_X86_64_RELATIVE 620
000000200e50 000000000008 R_X86_64_RELATIVE 5e0
000000201028 000000000008 R_X86_64_RELATIVE 201028
000000200fd8 000200000006 R_X86_64_GLOB_DAT 0000000000000000 b + 0
000000200fe0 000300000006 R_X86_64_GLOB_DAT 0000000000000000 __cxa_finalize + 0
000000200fe8 000400000006 R_X86_64_GLOB_DAT 0000000000000000 _ITM_registerTMCloneTa + 0
000000200ff0 000500000006 R_X86_64_GLOB_DAT 0000000000000000 _ITM_deregisterTMClone + 0
000000200ff8 000600000006 R_X86_64_GLOB_DAT 0000000000000000 __gmon_start__ + 0
Relocation section '.rela.plt' at offset 0x4c8 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000201018 000100000007 R_X86_64_JUMP_SLO 0000000000000000 ext + 0
000000201020 000a00000007 R_X86_64_JUMP_SLO 000000000000062a bar + 0
这个入口0x00201018放什么内容?如果按 GOT 逻辑,那自然就是引用的 ext 的地址;
但是 plt 机制里,放的是下1条指令pushq $0x0的地址,第 1 次执行时,也就是直接执行下一条了,跟没 jump 一样.
pushq 0x0 后,接下来跳转到.plt 里执行:
0000000000000510 <.plt>:
510: ff 35 f2 0a 20 00 pushq 0x200af2(%rip) # 201008 <_GLOBAL_OFFSET_TABLE_+0x8>
516: ff 25 f4 0a 20 00 jmpq *0x200af4(%rip) # 201010 <_GLOBAL_OFFSET_TABLE_+0x10>
51c: 0f 1f 40 00 nopl 0x0(%rax)
这个地方更奇怪了, 大意是把 0x201008 地址的东西压栈,然后调用了 0x201010
而这个 2 个地址都是位于 GLOB_DAT 和 JUMP_SLOT 之间的gmonstart的数据上.
最终还是回到了 GOT!
0000000000200ff8 R_X86_64_GLOB_DAT __gmon_start__
0000000000201018 R_X86_64_JUMP_SLOT ext
所有的神奇都在这里了,实际上就是跳转到了某个神秘的函数,_dl_runtime_resolve,同时给这个函数 push 了参数,(参数应该即使关于 ext 和它所在模块的基本信息),这个函数在 plt 后,执行了真正的地址定位,并且执行第 1 次的 ext.最最重要的,它会修改 ext@plt 的地址,写成实际的 ext 地址,这样下 1 次再运行时,就不用 plt 机制了,直接执行,至此,plt 机制退居幕后,完美的生效。
把初始化放到第 1 次运行才绑定,就是惰性的概念,也是延迟的由来.
这个机制不单针对引用外部函数,共享模块内的同样也可以,都可以让动态链接初次少干点活,加快速度. 也就是第 1 种情况,即 bar@plt 存在的原因.
其他问题
全局符号介入
//a1.c
//gcc -fPIC -shared a1.c -o a1.so
void a(){printf("a1.c");}
//a2.c
//gcc -fPIC a2.c -o a2.so
void a(){printf("a2.c");}
//b1.c
//gcc -fPIC -shared b1.c a1.so -o b1.so
void a();
void b1(){a();}
//b2.c
//gcc -fPIC -shared b2.c a2.so -o b2.so
void a();
void b2(){a();}
//main.c
//gcc main.c -shared b1.so b2.so -o main -XLinker -rpath ./
void main()
{
b1();
b2();
}
问题描述:
b1.so-->a in a1
b2.so-->a in a2
main-->b1 -->ld加载符号a到全局符号表
main-->b2-->又遇到1个符号a,怎么办?
./main &
a1.c
a1.c
此时 ld 会忽略第 2 个 a 的符号,也就是 b2.so 引用的 a 符号来自全局符号表中已有的 a 符号.
先装载的优先,后来的符号被忽略,这就是全局介入,也叫装载优先.
再看上面的 foo->bar,即内部调用,为啥也用 bar@plt 的机制,而不是直接相对地址调用?
把 bar 看成上面的符号 a,按全局介入的规则,即第 1 次的 bar 已经在全局符号表了,又采用了相对地址调用,那就得修改调用第 2 次 bar 时的地址,又重定位了,和地址无关冲突了.
所以干脆把内部调用处理为 bar@plt,这样统一后,不会引起冲突,全局介入性质满足.
共享模块的全局变量
假设在 solib.c 里定义 1 个全局变量,其他模块 m.c 假设引用了,这个全局变量:
// in m1.c
extern int global_v;
void bar()
{
global_v = 100;
}
...
// in m2.c
void bar2()
{
global_v = 200;
}
问题是,m.c 编译 m.o 时,分不清楚 global_v 到底是来自某个 so 的 got,还是其他普通 obj 文件? 这个地址就必须要运行前确定下来,而 so 里是没法确定的.
怎么办?
- m.c 是可执行文件的一部分
只能把这个全局变量拷贝 1 份副本,放在 efl 的.bss 段里,而且所有使用这个变量的指令引用时,都要指向这个副本.
而对于 so 来讲,再像前面的引用外部数据一样,动态链接时,ld 应该把这个全局变量的副本的地址也放到 GOT 里.,通过 GOT 实现变量的访问.
- m.c 是 so 的一部分
结论和上面的是一致的,因为这个全局变量,仍然可能被外部引用.
划重点:定义在共享库里的全局变量,在各自引用它的进程里,拷贝有副本,相互不影响,而线程的话,则是同1个副本,即A对gloval_v的改变会让B看到.
实际上,进程间也有共享数据段的需求—->共享数据段.
线程间也有各自存储数据的需求–>线程私有存储.
数据段地址无关码
前面讲的都是代码无关码,数据段如果包含对绝对地址引用:
static int a;
static int * p = &a;
那就只能老实的装载重定位了,可见 PIC 不能完全取代装载重定位,下面 2 种场景一定是要装载重定位的:
1. 有上述的数据对绝对地址的引用
2. 编译时,没有关闭了-fPIC编译(默认是打开的)
默认情况,只要链接了动态库,都会产生 PIC 代码,省代码段,省空间,何乐不为.
动态链接相关段
- .got .got.plt
GOT 在实际中分了两个表的:数据和函数,
.got 存放引用外部变量的表
.got.plt 存放引用外部函数的表.
.got.plt 稍微有点复杂. 按书上是说,表头 3 项是系统指定的:
1. .dynamic表位置
2. 本模块名称
3. plt地址解析函数入口地址_dl_runtime_resove()_
4. 其他函数入口

但在我的机器上,根本看不出.got.plt 里有啥.
- .plt .plt.got
还有其他几个表,名称接近,区分下:
.plt: 存放了一小段plt机制的执行代码
.plt.got: 一段代码,干嘛的未知.
.plt.got:
➜ compile-link-lib objdump -j .plt.got -d solib.so
solib.so: file format elf64-x86-64
Disassembly of section .plt.got:
0000000000000540 <__cxa_finalize@plt>:
540: ff 25 9a 0a 20 00 jmpq *0x200a9a(%rip) # 200fe0 <__cxa_finalize>
546: 66 90 xchg %ax,%ax
另外的:
.symtab : 静态链接处理的符号表
.dynamic: 动态链接器ld所需要的基本信息(总览)
.dynsym: 只保存动态链接处理的符号
.rela.text 静态链接,需要重定位的函数的入口表
.rela.data 静态链接,需要重定位的数据的入口表
.rela.dyn 动态链接下采用装载重定位时的重定位函数入口和数据入口
.rela.plt 动态链接重定位引用的函数入口.ext(bar也当成这类函数了)
.hash 用来加速符号查找的
- .dynamic 给出动态链接总体信息,有点像普通 elf 文件的文件头,静态 obj 肯定没有的.
➜ compile-link-lib readelf -d solib.so
Dynamic section at offset 0xe58 contains 20 entries:
Tag Type Name/Value
0x000000000000000c (INIT) 0x4f8
0x000000000000000d (FINI) 0x664
0x0000000000000019 (INIT_ARRAY) 0x200e48
0x000000000000001b (INIT_ARRAYSZ) 8 (bytes)
0x000000000000001a (FINI_ARRAY) 0x200e50
0x000000000000001c (FINI_ARRAYSZ) 8 (bytes)
0x000000006ffffef5 (GNU_HASH) 0x1f0
0x0000000000000005 (STRTAB) 0x380
0x0000000000000006 (SYMTAB) 0x230
0x000000000000000a (STRSZ) 135 (bytes)
0x000000000000000b (SYMENT) 24 (bytes)
0x0000000000000003 (PLTGOT) 0x201000
0x0000000000000002 (PLTRELSZ) 48 (bytes)
0x0000000000000014 (PLTREL) RELA
0x0000000000000017 (JMPREL) 0x4c8
0x0000000000000007 (RELA) 0x408
0x0000000000000008 (RELASZ) 192 (bytes)
0x0000000000000009 (RELAENT) 24 (bytes)
0x000000006ffffff9 (RELACOUNT) 3
0x0000000000000000 (NULL) 0x0
- .hash 加速查找:
➜ compile-link-lib readelf -sD solib.so
Symbol table of `.gnu.hash' for image:
Num Buc: Value Size Type Bind Vis Ndx Name
7 0: 0000000000000648 27 FUNC GLOBAL DEFAULT 10 foo
8 0: 0000000000201030 0 NOTYPE GLOBAL DEFAULT 19 _edata
9 0: 0000000000201038 0 NOTYPE GLOBAL DEFAULT 20 _end
10 0: 000000000000062a 30 FUNC GLOBAL DEFAULT 10 bar
11 1: 00000000000004f8 0 FUNC GLOBAL DEFAULT 7 _init
12 1: 0000000000201030 0 NOTYPE GLOBAL DEFAULT 20 __bss_start
13 2: 0000000000000664 0 FUNC GLOBAL DEFAULT 11 _fini
- .rela.dyn 和.rela.plt:
.rela.dyn 重定位符号入口,对.got
.rela.plt 也是重定位符号入口,对.got.plt 的重定位
got 表需要被 ld 修改,理解为对.got 的重定位是没问题的.
➜ compile-link-lib readelf -r solib.so
Relocation section '.rela.dyn' at offset 0x408 contains 8 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000200e48 000000000008 R_X86_64_RELATIVE 620
000000200e50 000000000008 R_X86_64_RELATIVE 5e0
000000201028 000000000008 R_X86_64_RELATIVE 201028
000000200fd8 000200000006 R_X86_64_GLOB_DAT 0000000000000000 b + 0
000000200fe0 000300000006 R_X86_64_GLOB_DAT 0000000000000000 __cxa_finalize + 0
000000200fe8 000400000006 R_X86_64_GLOB_DAT 0000000000000000 _ITM_registerTMCloneTa + 0
000000200ff0 000500000006 R_X86_64_GLOB_DAT 0000000000000000 _ITM_deregisterTMClone + 0
000000200ff8 000600000006 R_X86_64_GLOB_DAT 0000000000000000 __gmon_start__ + 0
Relocation section '.rela.plt' at offset 0x4c8 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000201018 000100000007 R_X86_64_JUMP_SLO 0000000000000000 ext + 0
000000201020 000300000007 R_X86_64_JUMP_SLO 0000000000000000 printf@GLIBC_2.2.5 + 0
000000201028 000a00000007 R_X86_64_JUMP_SLO 000000000000062a bar + 0
动态链接的流程
1. ld启动,但是它不能给自己重定位
2. 完成启动后,准备好了,才可以调用自己的函数,数据等.
3. 装载共享对象
-合并所有符号到全局符号表,深入优先的图结构.
4. 重定位
-地址无关码的话,就是修正.got.plt .got里的值,也可以叫GOT重定位
5. 执行so里的.init代码 , if any.
显示运行时装载
这个应该不陌生了:
void* dlopen(const char* filename,int flag);
void* dlsym(void* handle, char* symbol);
void* dlerror();
void* dlclose(void* handle);
