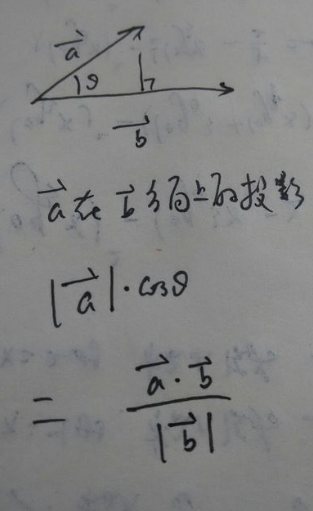统计学习方法 Ch1
统计学习主要指的监督学习.
基于假设:输入X与输出 Y 随机变量具有联合概率密度分布,但是具体的$P(X,Y)$是不好计算的.
问题形式化
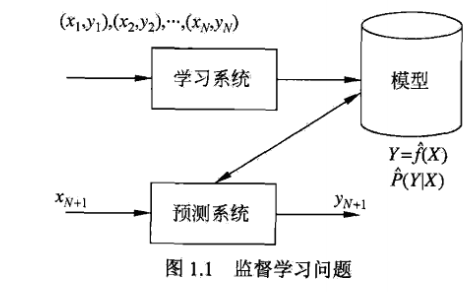
给定训练数据集: \(T={(x_{1},y_{1}),(x_{2},y_{2}),...(x_{n},y_{n})}\)
其中$xi$是输入观测值,$yi$是输出观测值,通过学习训练后得到模型,表示为一个条件概率分布$P(X,Y)$或者决策函数$Y=f(X)$;
在接下来的预测过程中,给定$x_{n+1}$,由模型: \(y_{n+1}=arg\ \underset{y_{n+1}}{max}(P(y_{n+1}|x_{n+1}))\) 得到输出\(y_{n+1}\).
方法=模型+策略+算法
模型就是要学习的条件概率分布或决策函数.
策略是如果去选择最优模型,用代价函数衡量预测错误的程度,记为$L(f(X),Y)$.
算法是求解最优解的算法.如果保证找到全局最优解,最高效。
经验损失最小化
期望损失定义为:
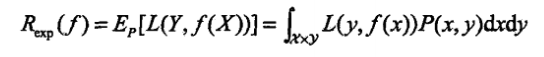
学习的目标就是找到期望损失最小的模型。
经验损失是训练样本的平均损失,去逼近期望损失.
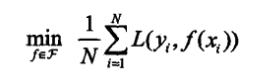
当模型是条件概率模型,损失函数为对数损失函数时,经验风险最小化就是极大似然估计.
结构风险最小化(正则化)
训练样本数据有限,往往需要修正经验损失,增加惩罚项.
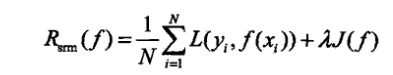
问题变成了下面的最优解的问题:
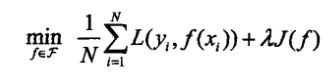
惩罚项也叫正则化项,可以是参数向量的 L1 or L2 范数。
比如,L1 范数为正则化项:
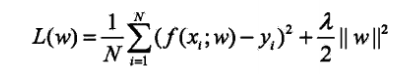
交叉验证
选择模型时,随机将数据切分为训练,测试,和验证集合,验证集合用来选择模型,训练集合用来得到模型,测试集合对训练结果进行评估.
- 简单如 7/3 分
- 随机 S 等分,用 S-1 个训练,用 1 个测试,选 S-1 个里最好的
泛化能力
即对未知数据的预测能力,往往用测试误差来评价泛化能力。
生成模型和判别模型的概念
生成模型使用联合概率建模,判别模型直接使用条件概率建模.
极大似然估计
数学补课
为什么看超平面?因为感知机算法里提到了这个概念.
超平面
向量投影计算: