
Deep learning Fastai Lesson1 Image classifier
- data 的组织形式
- Precompute and freeze
- Choosing a start learning rate
- Stochastic gradient descent with restarts.(SGDR)
data 的组织形式
1 种是 按文件夹分类,train valid 下有 dog 和 cat 类; test 下全是 jpg,分类就是将 jpg 像 train 文件夹下面一样按类放好.
另 1 种是常见的 image + lable 分开的情况.
这两种情况,fastai 都考虑到了,调用不同的接口即可:
ImageClassifierData.from_paths(...)
ImageClassifierData.from_csv(...)
还有直接从内存 load 的
ImageClassifierData.from_array(...)
A blog for help,再理解下.
a model created by some one else to solve a different problem
几种境界:
复用已经 train 好的 model,毕竟能分类 1000 种 (resnet34)
替换 output layerk,如调整个数,重新 train weights (pretrain model)
freeze 前面 n-k 层,train 后面 k 层 weights
网络基本结构不变,改下层数,重新训练所有层 weights(resnet18,resnet34,reset101…)
新的轮子!(leNet,GoogleNet,VGG,RestNet,ResNext…)
fastai 的例子是在第 2 和第 3 种境界里,不过大部分场景可能都够用了.
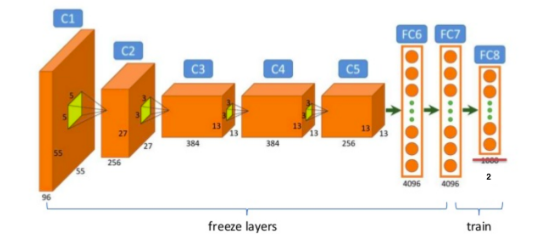
Precompute and freeze
- freeze
Make all layers untrainable (i.e. frozen) except for the last layer.
freeze 意味着 training 过程,仅更新 last output layer 的 weights,而不更新第 1 到 n-1 层的 weights(除去 output layer).
从 ImamgeNet 这种巨无霸训练出来的 pretrained model(如 resnet)仅调整 last layer,对 image classification 这种任务,就可以有很好的效果.
arch=resnet34
data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(arch, sz))
learn = ConvLearner.pretrained(arch, data, precompute=True)
learn.fit(0.01, 2)
- unfreeze
Make all layers trainable by unfreezing. This will also set the precompute = False since we can not longer pre-calculate the activation of frozen layers.
unfreeze 相反,training 时会更新所有 layer 的 weights,如果是 pretrain,则在 pretrain model 的 weights 基础上,这其实就是普通模型 traning 时最一般的情况。
unfreeze 会将 precompute= False; 因为这两者是冲突的,有 unfreeze 就没有 precompute
同理,下面提到的data augmentation同 precomputed=True 也是冲突的。一旦 precomputed=True,augmentation 就没有效果,重点看这个 data
class ConvLearner(Learner)
def __init__(self,...)
if precompute: self.save_fc1()
...
@property
def data(self): return self.fc_data if self.precompute else self.data_
- precompute
precompute 是 pretrain 前提下的一种优化手段,就是提前计算了 freeze 掉的 1 到 n-1 层的 weights forward 计算出来的值,叫precomputed activations
I perfectly understood now. The precompute is avoiding the model to recalculate the
activation values for every image over all the previous frozen layers ( it calculates
for the first time and saves in a temporary directory ). This way, we can just play
around with the last (unfrozen) layers much faster. Such a smart trick…`
Precomputed = True, means reuse precomputed activations.
if we use precompute = True, then freeze / unfrozen do not work as we operate only on
already calculated outputs of conv layers.
also data augmentation do not work
in order to use data augmentation and fine tune conv layers we need to start with
precompute=False
in this case by default all conv layers are freezed
再看代码。precompute=True 时 fc_data 来自save_fc1.
save_fc1在init,or 调用 set_data 时,执行 1 次.
def set_data(self, data, precompute=False):
super().set_data(data)
if precompute:
self.unfreeze()
self.save_fc1()
self.freeze()
self.precompute = True
else:
self.freeze()
针对 data set 的每一个 x, save_fc1计算前面提到的 precomputed activations,并保存。 1 个 epochs 也许没啥优化效果,但多个 epochs 时(epochs 可以认为是 train data 重复训练多少次),就不用重复计算这些值,得到了优化。
注意的是,如果是为了 train last layer,可以考虑 precomputed=True,但如果是 fine tune 整个网络,记得 precomputed=False 和 unfreeze.(包含了 precompute=False)
def save_fc1(self):
self.get_activations()
act, val_act, test_act = self.activations
#top model就是除了last layer外的pretrain model
m=self.models.top_model
if len(self.activations[0])!=len(self.data.trn_ds):
#这里就是在提前计算precompute activations
predict_to_bcolz(m, self.data.fix_dl, act)
if len(self.activations[1])!=len(self.data.val_ds):
predict_to_bcolz(m, self.data.val_dl, val_act)
if self.data.test_dl and (len(self.activations[2])!=len(self.data.test_ds)):
if self.data.test_dl: predict_to_bcolz(m, self.data.test_dl, test_act)
#这里就是把load好的activation val放到fc_data,即model.data,给后续使用
self.fc_data = ImageClassifierData.from_arrays(self.data.path,
(act, self.data.trn_y), (val_act, self.data.val_y), self.data.bs, classes=self.data.classes,
test = test_act if self.data.test_dl else None, num_workers=8)
Choosing a start learning rate
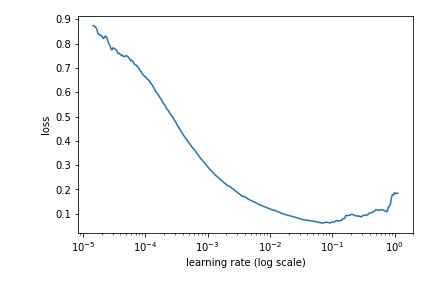
- lr and cost function 一种确定 lr 方法,逐步增加学习率,观察损失函数的翻转时期,如果发生翻转,用翻转前一点的 lr 作为最佳学习率
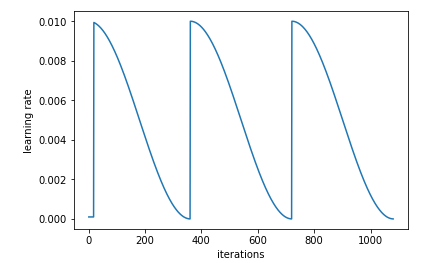
Stochastic gradient descent with restarts.(SGDR)
在接近 local minima 时,流行的做法是逐渐减少 lr.
一个更合适的方法是用 half cos 函数(cosine annealing 的由来)来拟合 iteration 和 lr 关系.iteration 越大,lr 下降的越平缓,而刚开始时,允许 lr 快速下降,加速迭代。
并且,为了防止掉到一些不佳的 local minima 中,最后的 lr 可以 jump 一下,即增加 lr 跳出 local minima,而是 restart 的含义。
learn.fit(1e-2, 3, cycle_len=1)
cyclen_len 是多少个 epochs reset1 次上面说的 learning rate.
Data augmentation
为防止 overfit,可考虑在训练前增加样本,增加的样本来自原样本的 slight 仿射变换(太大的变换导致特征变形,不妥).旋转,平移,翻转等,
不同种类的样本,变换的形式可能不一样,dog and cat 没有翻转的..icgberg 就有翻转的.and so on.
对图像以外的 data augmentation 可不一定管用,如 nlp,刚刚也在想这个问题,如果是线性回归,SVM 之类的,如果改变了 data 的空间,势必影响分类结果.
image 之所以有用,是因为人类眼睛已经锁定了图像特征,对各种变换的图像仍然会正确标注,所以通过变换来增加样本容量是 resonable 的.
由此想到中文 nlp 也是很神奇,..也可以变换!你不会为认我下面的打字的会有什么题问...
data augmentation 也是针对 last layer 做的
Test time augmentation(TTA)
uses the original image along with 4 randomly augmented versions). It then takes the average prediction from these images.
TTA 用 data augmentation 的思路去扩充 valadation dataset.
比如每个样本扩充了 10 个变形,validation set 扩充 10 倍,each sample 取平均,看预测效果是否改善,使得评估更准确,这里并没有改变已经训练好的 model.
学生提问 data augmentation 里,如果是 crop,要丢失信息?Howard 建议是把图片弄大点再 crop..这样不丢失.
Differential learning rate annealing
越靠前的层发现的特征比较粗犷,更有普适性,学习率可以低一点,(参数不需要调整太多),后面的层特征越精细,越需要调整.
learn.unfreeze()
lr=np.array([1e-4,1e-3,1e-2]);
learn.fit(lr, 3, cycle_len=1, cycle_mult=2)
另外按越到后面,速率的调整越慢,越精细的思想:
前面 SGDR 方法的 restart 的宽度也可以调整, cycle_mult =2,即每个 cycle 都 2 倍增加 jump 的宽度.
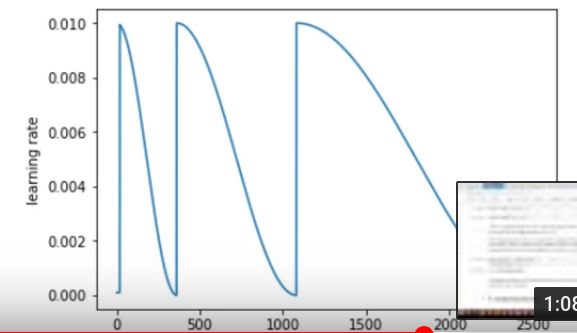
这个 trick 效果很好.
有学生提到了和gridsearch的区别。应该就是 sklearn 里的GridSearchCv,后者用来找最佳超参数的,而dlra是已经确定了3个 best lr,然后用来不同的 layer 上
有人提到了图片的 size,Howard 提到了 fast ai 可以搞定任何 size 的图片…我猜应该是预处理将所有的 size 图片 adjust to uniform value as input layer,like 224x224?
到这里,full model has been trained.
Analyzing results with confusion matrix
应该就是真值表,precision,recall,F1 这些指标. True-True,True-false False-True, False-False;
To sumerise
to train a better image classifier:

