
Deep learning Fastai Lesson6 Rnn
RNN 模型演进
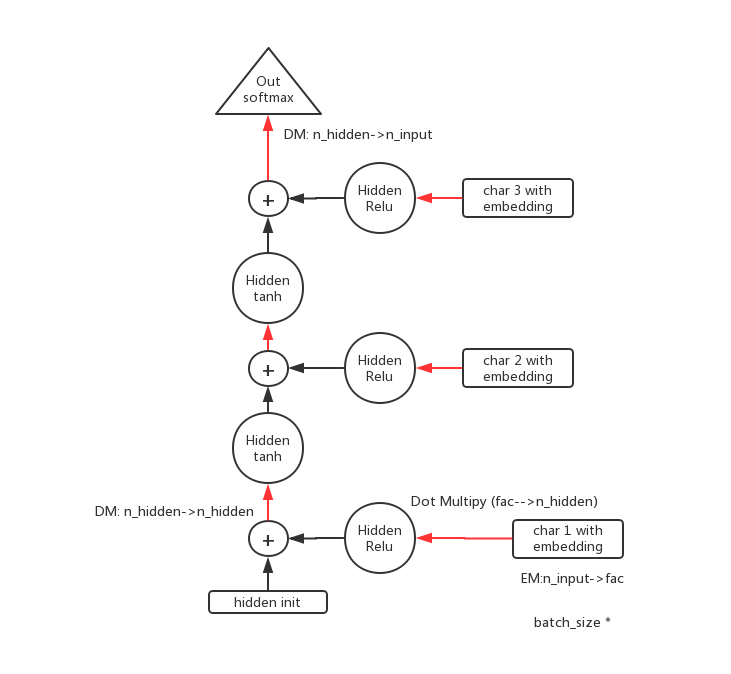
hidden 内部展开
class BrChar3Model(nn.Module):
def __init__(self,vocab_size,n_fac,n_hidden):
super().__init__()
self.em = nn.Embedding(vocab_size,n_fac)
self.l_in = nn.Linear(n_fac,n_hidden);
self.l_hidden = nn.Linear(n_hidden,n_hidden)
self.l_ho = nn.Linear(n_hidden,vocab_size)
def forward(self,c1,c2,c3):
in1 = F.relu(self.l_in(self.em(c1)))
in2 = F.relu(self.l_in(self.em(c2)))
in3 = F.relu(self.l_in(self.em(c3)))
h = V(torch.zeros(in1.size()).cpu())
h = F.tanh(self.l_hidden(h+in1))
h = F.tanh(self.l_hidden(h+in2))
h = F.tanh(self.l_hidden(h+in3))
return F.log_softmax(self.l_ho(h))
输入及 forward
let n_hidde=256,fac=42,n_input=85
1 个样本的 forward 计算过程:
输入 X0 = [‘g’,’o’,’o’,] predict=’d’.
对每个 x in X0,
1x1–Embedding->1x42–input_hidden->1x256.
经过 add hidden 后,维度不变,1x256-hidden_output->1x85
最终的结果 1x85-softmax->1x85->max->1,如np.argmax(to_np(res))
即 85 个结果中,最可能的那个.
3这个维度代表的是时间 t,如[x1 x2 x3]=[‘g’,’o’,’o’]
取 1 个 batch 的数据,此时应该为输入512x3按上面分析,最终得到的 forward result 应该是512x85
md = ColumnarModelData.from_arrays('.', [-1], np.stack([x1,x2,x3], axis=1), y, bs=512)
it = iter(md.trn_dl)
*xs,yt = next(it)
折叠起来
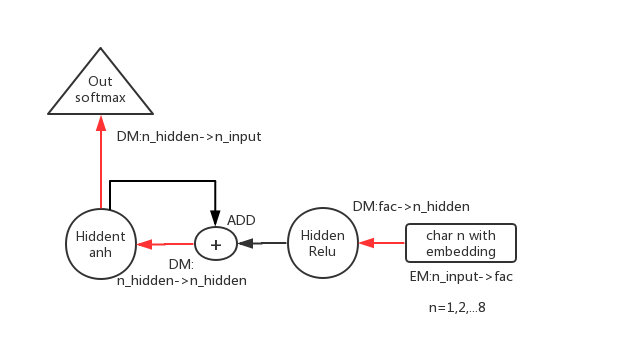
即 rnn 里 r 的含义,Recurrent,对于 hidden 层:这一时刻的 h 的输出,联同下一时刻的系统输入,作为下一时刻 h 的输入
class CharLoopModel(nn.Module):
# This is an RNN!
def __init__(self, vocab_size, n_fac):
super().__init__()
self.e = nn.Embedding(vocab_size, n_fac)
self.l_in = nn.Linear(n_fac, n_hidden)
self.l_hidden = nn.Linear(n_hidden, n_hidden)
self.l_out = nn.Linear(n_hidden, vocab_size)
def forward(self, *cs):
bs = cs[0].size(0)
h = V(torch.zeros(bs, n_hidden).cpu())
for c in cs:
inp = F.relu(self.l_in(self.e(c)))
h = F.tanh(self.l_hidden(h+inp))
return F.log_softmax(self.l_out(h), dim=-1)
输入及forward
输入序列I love this game,输入前 8 个时刻,预测第 1 个时刻。
但是下一个数据是 overlap 的,应该是下面这个样子的矩阵:
['I',' ','l','o','v','e',' ','t']
[' ','l','o','v','e',' ','t','h']
['l','o','v','e',' ','t','h','i']
['o','v','e',' ','t','h','i','s']
['v','e',' ','t','h','i','s',' ']
['e',' ','t','h','i','s',' ','g']
除了序列的长度变了,其余同上一个分析,因此 1 个 batch 最后的输出仍然是512x85
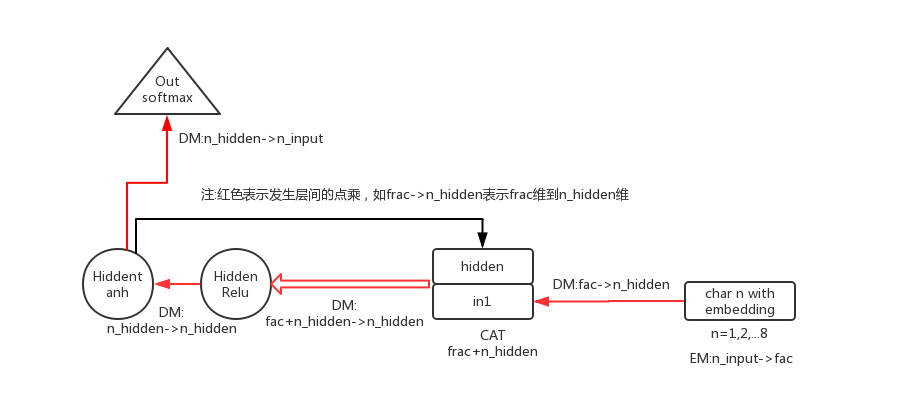
hidden 的输入 concat
这样效果比上面的要更好一点.在 input 到 hidden layer 时,就将 h 和 origin input 做 concat 了。
class CharLoopConcatModel(nn.Module):
def __init__(self, vocab_size, n_fac):
super().__init__()
self.e = nn.Embedding(vocab_size, n_fac)
self.l_in = nn.Linear(n_fac+n_hidden, n_hidden)
self.l_hidden = nn.Linear(n_hidden, n_hidden)
self.l_out = nn.Linear(n_hidden, vocab_size)
def forward(self, *cs):
bs = cs[0].size(0)
h = V(torch.zeros(bs, n_hidden).cuda())
for c in cs:
inp = torch.cat((h, self.e(c)), 1)
inp = F.relu(self.l_in(inp))
h = F.tanh(self.l_hidden(inp))
return F.log_softmax(self.l_out(h), dim=-1)
pytorch 里的 RNN
和上面的完全一致,不过用 RNN 做了封装.代码更简洁
class CharRnn(nn.Module):
def __init__(self, vocab_size, n_fac):
super().__init__()
self.e = nn.Embedding(vocab_size, n_fac)
self.rnn = nn.RNN(n_fac, n_hidden)
self.l_out = nn.Linear(n_hidden, vocab_size)
def forward(self, *cs):
bs = cs[0].size(0)
h = V(torch.zeros(1, bs, n_hidden))
inp = self.e(torch.stack(cs))
outp,h = self.rnn(inp, h)
return F.log_softmax(self.l_out(outp[-1]), dim=-1)
注意:
outp,h = self.rnn(inp, h)
上面的模型里,实际上 rnn 层的每个循环可以有中间结果的输出,多少个循环,取决于 forward 的输入 cs 被 stack 了多少个维度. 比如:
1 个 batch 512,输入8x512 (not 512x8)? outp 则为8x512x256, h 为1x512x256
Multiout Model(SeqRNN)
如果把数据的输入换成 non-overlap 的,然后考虑每个时刻的对下一时刻的预测,(即上面提到的中间输出)
input training data
SUPPOS
ING that
Truth i
s a woma
n--what
then? Is
there n
ot groun
label data
SUPPOSI
NG that
Truth is
a woman
--what t
hen? Is
there no
t ground
模型为:
class CharSeqRnn(nn.Module):
def __init__(self, vocab_size, n_fac):
super().__init__()
self.e = nn.Embedding(vocab_size, n_fac)
self.rnn = nn.RNN(n_fac, n_hidden)
self.l_out = nn.Linear(n_hidden, vocab_size)
def forward(self, *cs):
bs = cs[0].size(0)
h = V(torch.zeros(1, bs, n_hidden))
inp = self.e(torch.stack(cs))
outp,h = self.rnn(inp, h)
return F.log_softmax(self.l_out(outp), dim=-1)
注意 forward 的最后一行的输出与普通 RNN 的区别
用单位 I 矩阵初始化 h
对于 pytorch 的 RNN,如此初始化系数效果好
m = CharSeqRnn(vocab_size, n_fac).cuda()
opt = optim.Adam(m.parameters(), 1e-2)
m.rnn.weight_hh_l0.data.copy_(torch.eye(n_hidden))
