
Zeromq 1个具体应用
场景
n 个集群构成的云,每个单点(A cluster)计算能力不一,都运行了 clients 和 workers.
clients 可同时向 workers 发送 task,若单点本身无可用 worker,向其他空闲单点发送 task. worker 处理完毕后,向 clients 发送 reply;
单点随时可能移除(crash)和上线(add),弹性伸缩能力!
单点(Cluster)实现
单点就用前面提到的 load balancing broker:
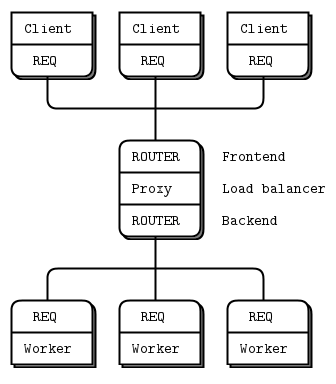
这个 single cluster 的问题是 worker 太慢,(pop 前可以看到 workers list 里的 worker 越来越少,最后肯定是 client 等待 worker).
如果有 multiple cluster,把当前 broker 处理不过来的 client 交给其他 broker 的 worker 处理,岂不美哉?
Multiple Clusters
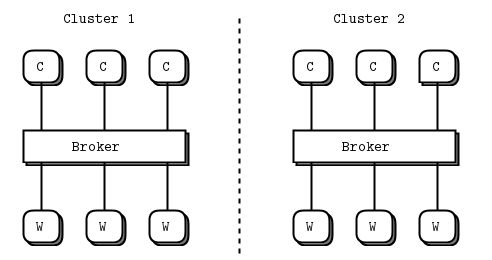
多点怎么办?client 需要和另外的 broker 通信;workers 需要告诉其他 broker”我有空”,broker 之间也需要交流.
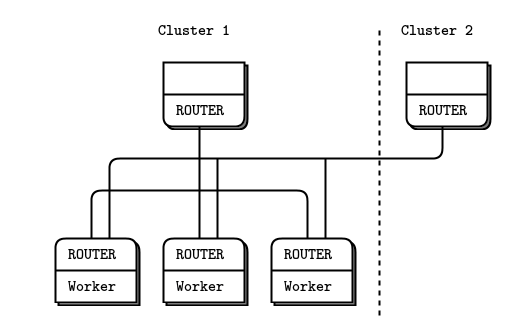
worker 的 REQ 变成 ROUTER
原模型的 REQ 只能通知1个 ROUTER(proxy), 将 worker 改为 ROUTER 后,ROUTER->ROUTER.可以 routing 的方式通知多个 broker;
broker 之间
borker 之间可用额外的 network type 保持沟通.甚至增加 broker center 来与所有 broker 交互.
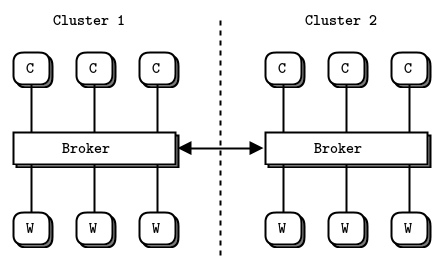
假设 n 个 broker,每个 broker 有 n-1 个 peer,看下 broker 之间可能发生的交流:
- PUB-SUB, 告诉 or 接收 peer broker 可用的 worker 数量和状态;
- 1 ROUTER for tasks it receives
- 1 ROUTER for tasks it delegates(委托给其他 broker)
所有3个 type ,双向,一共有6个方向的数据流.
结合 load balancing broker 内部的数据流,1 个 broker 有3大类 flows:
- A local request-reply flow between the broker and its clients and workers.(正常的 load balancing flow)
- A cloud request-reply flow between the broker and its peer brokers.(broker 提交 task 到其他 broker)
- A state flow between the broker and its peer brokers.(告诉其他 broker 有多少空闲 workers)
完整的 broker 构成:
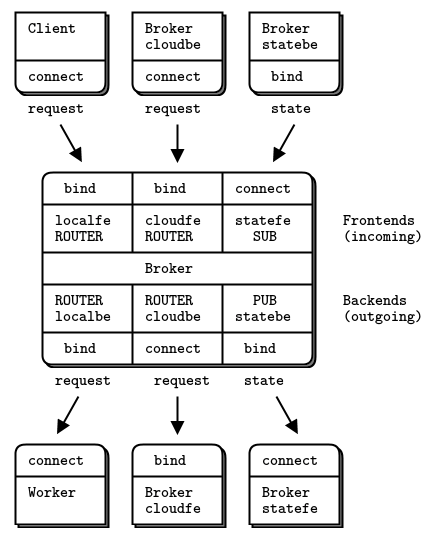
state flow
PUB bind, SUB connect
PUB 给对方什么?peer+当前还有多少 worker,worker 数量发生变化时就 pub
cloud and local flow
local worker Reply 时,local_cap +=1; cloud worker 则是通过上面的 state flow 将[peer,cap],如果有多个,将 cap 用 list 保存下.
当 local_cap+cloud_cap 不为0时,说明 worker ready,开始 frontend 的 poll,同样可能来自 local or cloud;
这里有个策略问题,client 是发给 cloud 还是 local 的 worker 处理? 自然的想法是先 local 处理了,local 处理不过来,再去找 cloud.具体多个 cloud 怎么找?例子用的 random,理论上应该看谁的 cap 最大,自然最稳妥了.
while local_capacity + cloud_capacity:
secondary = zmq.Poller()
secondary.register(localfe, zmq.POLLIN)
if local_capacity:
secondary.register(cloudfe, zmq.POLLIN)
events = dict(secondary.poll(0))
# We'll do peer brokers first, to prevent starvation
if cloudfe in events:
msg = cloudfe.recv_multipart()
elif localfe in events:
msg = localfe.recv_multipart()
else:
break # No work, go back to backends
if local_capacity:
msg = [workers.pop(0), b''] + msg
localbe.send_multipart(msg)
local_capacity -= 1
else:
# Route to random broker peer
msg = [random.choice(peers), b''] + msg
cloudbe.send_multipart(msg)
if local_capacity != previous:
statebe.send_multipart([myself, asbytes(local_capacity)])
完整的例子:
import random
import sys
import threading
import time
import zmq
NBR_CLIENTS = 100
NBR_WORKERS = 8
def asbytes(obj):
s = str(obj)
if str is not bytes:
# Python 3
s = s.encode('ascii')
return s
def client_task(name, i):
"""Request-reply client using REQ socket"""
ctx = zmq.Context()
client = ctx.socket(zmq.REQ)
client.identity = (u"Client-%s-%s" % (name, i)).encode('ascii')
client.connect("ipc://%s-localfe.ipc" % name)
monitor = ctx.socket(zmq.PUSH)
monitor.connect("ipc://%s-monitor.ipc" % name)
poller = zmq.Poller()
poller.register(client, zmq.POLLIN)
while True:
time.sleep(random.randint(0, 5))
for _ in range(random.randint(0, 15)):
# send request with random hex ID
task_id = u"%04X" % random.randint(0, 10000)
client.send_string(task_id)
# wait max 10 seconds for a reply, then complain
try:
events = dict(poller.poll(10000))
except zmq.ZMQError:
return # interrupted
if events:
reply = client.recv_string()
print("expected %s, got %s" % (task_id, reply))
assert reply == task_id, "expected %s, got %s" % (task_id, reply)
monitor.send_string(reply)
else:
monitor.send_string(u"E: CLIENT EXIT - lost task %s" % task_id)
return
def worker_task(name, i):
"""Worker using REQ socket to do LRU routing"""
ctx = zmq.Context()
worker = ctx.socket(zmq.REQ)
worker.identity = ("Worker-%s-%s" % (name, i)).encode('ascii')
worker.connect("ipc://%s-localbe.ipc" % name)
# Tell broker we're ready for work
worker.send(b"READY")
# Process messages as they arrive
while True:
try:
msg = worker.recv_multipart()
except zmq.ZMQError:
# interrupted
return
# Workers are busy for 0/1 seconds
time.sleep(random.randint(0, 1))
worker.send_multipart(msg)
def main(myself, peers):
print("I: preparing broker at %s…" % myself)
# Prepare our context and sockets
ctx = zmq.Context()
# Bind cloud frontend to endpoint
cloudfe = ctx.socket(zmq.ROUTER)
cloudfe.setsockopt(zmq.IDENTITY, myself)
cloudfe.bind("ipc://%s-cloud.ipc" % myself)
# Bind state backend / publisher to endpoint
statebe = ctx.socket(zmq.PUB)
statebe.bind("ipc://%s-state.ipc" % myself)
# Connect cloud and state backends to all peers
cloudbe = ctx.socket(zmq.ROUTER)
statefe = ctx.socket(zmq.SUB)
statefe.setsockopt(zmq.SUBSCRIBE, b"")
cloudbe.setsockopt(zmq.IDENTITY, myself)
for peer in peers:
print("I: connecting to cloud frontend at %s" % peer)
cloudbe.connect("ipc://%s-cloud.ipc" % peer)
print("I: connecting to state backend at %s" % peer)
statefe.connect("ipc://%s-state.ipc" % peer)
# Prepare local frontend and backend
localfe = ctx.socket(zmq.ROUTER)
localfe.bind("ipc://%s-localfe.ipc" % myself)
localbe = ctx.socket(zmq.ROUTER)
localbe.bind("ipc://%s-localbe.ipc" % myself)
# Prepare monitor socket
monitor = ctx.socket(zmq.PULL)
monitor.bind("ipc://%s-monitor.ipc" % myself)
# Get user to tell us when we can start…
# raw_input("Press Enter when all brokers are started: ")
# create workers and clients threads
for i in range(NBR_WORKERS):
thread = threading.Thread(target=worker_task, args=(myself, i))
thread.daemon = True
thread.start()
for i in range(NBR_CLIENTS):
thread_c = threading.Thread(target=client_task, args=(myself, i))
thread_c.daemon = True
thread_c.start()
# Interesting part
# -------------------------------------------------------------
# Publish-subscribe flow
# - Poll statefe and process capacity updates
# - Each time capacity changes, broadcast new value
# Request-reply flow
# - Poll primary and process local/cloud replies
# - While worker available, route localfe to local or cloud
local_capacity = 0
cloud_capacity = 0
workers = []
# setup backend poller
pollerbe = zmq.Poller()
pollerbe.register(localbe, zmq.POLLIN)
pollerbe.register(cloudbe, zmq.POLLIN)
pollerbe.register(statefe, zmq.POLLIN)
pollerbe.register(monitor, zmq.POLLIN)
while True:
# If we have no workers anyhow, wait indefinitely
try:
events = dict(pollerbe.poll(1000 if local_capacity else None))
except zmq.ZMQError:
break # interrupted
previous = local_capacity
# Handle reply from local worker
msg = None
if localbe in events:
msg = localbe.recv_multipart()
(address, empty), msg = msg[:2], msg[2:]
workers.append(address)
local_capacity += 1
# If it's READY, don't route the message any further
if msg[-1] == b'READY':
msg = None
elif cloudbe in events:
msg = cloudbe.recv_multipart()
(address, empty), msg = msg[:2], msg[2:]
# We don't use peer broker address for anything
if msg is not None:
address = msg[0]
if address in peers:
# Route reply to cloud if it's addressed to a broker
cloudfe.send_multipart(msg)
else:
# Route reply to client if we still need to
localfe.send_multipart(msg)
# Handle capacity updates
if statefe in events:
peer, s = statefe.recv_multipart()
cloud_capacity = int(s)
print('recv cloud worker from peer %s cap %d'%(peer,cloud_capacity))
# handle monitor message
if monitor in events:
print(monitor.recv_string())
# Now route as many clients requests as we can handle
# - If we have local capacity we poll both localfe and cloudfe
# - If we have cloud capacity only, we poll just localfe
# - Route any request locally if we can, else to cloud
while local_capacity + cloud_capacity:
print('Local %d Cloud %d' %(local_capacity, cloud_capacity))
secondary = zmq.Poller()
secondary.register(localfe, zmq.POLLIN)
if local_capacity:
secondary.register(cloudfe, zmq.POLLIN)
events = dict(secondary.poll(0))
# We'll do peer brokers first, to prevent starvation
if cloudfe in events:
msg = cloudfe.recv_multipart()
elif localfe in events:
msg = localfe.recv_multipart()
else:
break # No work, go back to backends
if local_capacity:
msg = [workers.pop(0), b''] + msg
localbe.send_multipart(msg)
local_capacity -= 1
else:
# Route to random broker peer
msg = [random.choice(peers), b''] + msg
cloudbe.send_multipart(msg)
if local_capacity != previous:
print("Pub to cloud peer %d left", local_capacity)
statebe.send_multipart([myself, asbytes(local_capacity)])
if __name__ == '__main__':
if len(sys.argv) >= 2:
myself = asbytes(sys.argv[1])
main(myself, peers=[ asbytes(a) for a in sys.argv[2:] ])
else:
print("Usage: peering3.py 1 2 3 4")
sys.exit(1)
特别注意 ROUTER 的使用:
send to router 时,消息第1个为 address(route 到那里去?)
router received 的消息第1个也一定是 address(指明哪里 route 过来的?)
如果来自 REQ address 后面肯定有 delimeter
缺陷
multibroker 都是直连的,增加 broker 时,拓扑太复杂了。显然设计1个 ceter borker 所有的 broker 跟它通信,由它统一调度的思路更清晰。
另外1个缺陷,即 load balancing 实现时,local worker 都是注册到了1个 list 中,poll 检出1个 worker,马上就用掉了,意味着其他 worker 在排队等待中,这导致 worker list 中最多1个 worker 在等待,效率不是太高.而且由于数量不变,并不会通过 state flow 通知其他 cloud broker,导致例子的演示效果不好.
灵感一下
看到了 redis cluster 的架构,是不是觉得就在眼前?
其他例子
client 访问 node server, node server 从另外的 python ml 处理拿预测结果, node.js <–zeromq–> python.
https://medium.com/@amit.kulkarni/consuming-services-for-web-using-zeromq-5d9817fec2cd
