
Web Celery基础
celery overview archtecture and how it works
前 l?不是一个层面的东西
任务队列是逻辑模型, 解决多个 tasks 如何更好的执行, 可以基于 MQ 实现
RPC 实现了远程任务的框架,同样可以基于 MQ 实现
MQ 是异构系统间最好的通信模型,封装了通信,消息存储,中转等
Celery
Celery 是 python 实现的优秀的异步任务队列框架.
如何优秀?考虑更全面,更稳健,更好用,随便举几个问题:
异步任务无回复怎么办?
可以监控异步任务吗?进度管理?
不想基于 Rabbitmq 实现,怎么办?
分布式异步任务可以吗?
精确的定时任务调度,星期几,week, year?
任务执行流(task chain)?
任务资源泄露怎么处理?
Celery 基于 queue 实现 Broker,支持 Rabbitmq,Redis 等
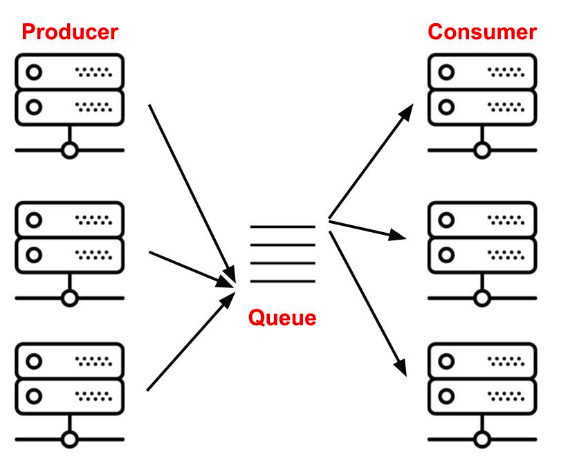
Broker 简单理解就是 MQ 里的 queue,对象被序列化后,就是存在 Broker 里, 反序列化后,再给真正执行任务的 Worker.
python 序列化工具: Pickle,Msgpack,Protobuf,JSON,yaml 等..
复杂 object,不要 serialized!可以存数据库,在 Worker 的 remote call 里 id 检索
4 个角色
Web, Broker,Result Backend, Worker
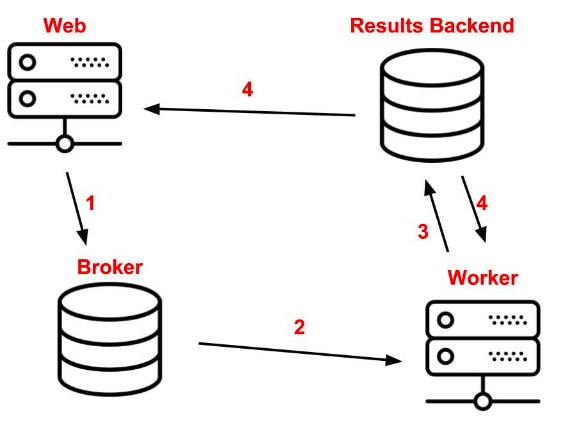
使用
普通用法就是异步原调,略
celery multi start -A tasks worker --loglevel=info
#python3.7 celery和redis有点兼容问题 用下面的命令
/root/miniconda3/envs/python36/bin/celery -A tasks worker --loglevel=info
高级用法有 group,chord,map,chain,starmap,chunks…听上去就够高级了.
#链式运行,前面的返回,作为后面的第1个输入
print('[Celery] chain tasks: ')
from celery import chain
chain( task1_fetch.s('a','b') | task2_process.s('c') | task3_store.s('d'))().get()
# task并行
print('[Celery] group')
from celery import group
g = group(add.s(i,i) for i in range(0,12))()
print(g.get())
print('[Celery] chord')
# 先执行group 后执行 callback, callback的第1个参数,来自前面的结果(这里是group)
from celery import chord
result = chord( [add.s(i,i) for i in range(0,10) ] )(add.s( [20] )).get()
print(result)
print('[Celery] starmap')
# zip的结果[ [1,1], [2,3]] ..map是1个task 执行完所有的组
result = ~add.starmap(zip(range(100), range(100)))
print(result)
from celery import chunks
# 原来需要 100个task 现在分成10个task 每个执行10个
print('[Celery] chunk')
chun = add.chunks(zip(range(100), range(100)), 10)()
print(chun.get())
疑问
但 celery 号称是分布式异步队列,没看出分布式体现在哪?task 定义了后,只能在本机 trigger:
from tasks import add,mult,some_task
add.delay(x,x)
也就是 trigger 和 task 都必须在一个机器上才行?
借用 RPC 可以实现远调异步,也就是 Celery+pika,借用 Rabiitmq 实现(实际上 task 和 trigger 仍然未分离)
Broker 和 Result Backend 是可以分布式的;
还是有人和我一样的疑问:
how to configure and run celery worker on remote system
scaling-celery-sending-tasks-to-remote
尝试一个方案:
Machain A:
Rabbitmq server, A和B当然也可以在一起
Machine B :
1 Install Celery 配置好celery的rabiitmq queue
2 Upload task.py
3 run `celery -A tasks worker `,即worker,(consumer)
Machine C :
1 Install Celery 配置好celery的rabiitmq queue
2 Upload task.py
3 run `celery -A tasks worker `,即worker,(consumer)
Machine D:
do nothing but want to trigger only?
1 Upload task.py
2 Trigger it (add.delay(1,2))
这样 D 想执行的任务会分散到 B 和 C 上,并且可以离线执行(因为有消息队列,任务)
所以 Celery 来做 RPC 完全可以的.但是其序列化手段不一定效率高,竟没看到支持 protobuf
